As we reached the end of the autumn term, our first teaching the new A-level specification, my thoughts started to turn to the shape of the second year of the course. We ended the term with a training day, for which we were given no agenda from above, so I decided to spend 3 hours of this ordering the topics for year 2. For this task I worked with Will, who I have been teaching the year 12 course with. We were again joined by Simon from MEI.
One thing that we have felt has held us back slightly this year is that our framework is different to that of other schools within the trust. This is partly due to the fact that we have different structures, we only have one group and are therefore sharing the teaching between the two of us, where the other schools have more than one group and have teachers who are involved in more than one group. This makes the close collaboration that we have been able to maintain much more difficult for them. We therefore decided to try and make our second year framework possible to split into two separate teachers running in parallel, rather than just our linear system, which is effectively just one teacher. This will hopefully allow other schools within the trust to adopt our order, allowing greater collaboration in the creation of resources and assessment materials.
The scheme of work allows for 4 weeks of study at the end of year 12, after AS examinations are complete. There are nominally 6 weeks available to us but experience tells us that at least two of these will be lost to whole school events.
 Our starting point was the detailed content statements from the DofE specification document. We had these cut up so that we could place them into our framework, shuffling as often as we needed. Our initial thoughts were to look for obvious connections in the content for topics that should take place close together. For example we decided that parametric equations would work well with parabolic motion. This led to us splitting the numerical methods topic into sections and placing these with other topics, for example putting the trapezium rule with integration. We then tried to place the topics into an order where any pre-requisites were taught first – surprisingly difficult with the way that the contents links together.
Our starting point was the detailed content statements from the DofE specification document. We had these cut up so that we could place them into our framework, shuffling as often as we needed. Our initial thoughts were to look for obvious connections in the content for topics that should take place close together. For example we decided that parametric equations would work well with parabolic motion. This led to us splitting the numerical methods topic into sections and placing these with other topics, for example putting the trapezium rule with integration. We then tried to place the topics into an order where any pre-requisites were taught first – surprisingly difficult with the way that the contents links together.
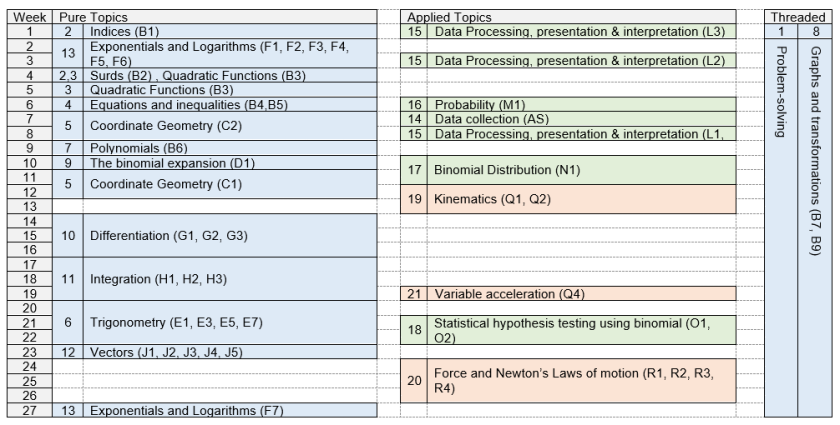
We wanted to put a large section of the trigonometry as early as possible as there are so many other topics that link back to it. The problem with having this so early is that we had not planned to have completed functions, something that links well with the inverse trigonometric functions. We decided to leave this order, but to use the inverse functions as our way in to functions, coming back to discuss the conditions that need to be placed on the domain and range. The order of topics is shown here:

In our model of having two teachers in parallel, rather than this linear structure we moved some additional content from the left hand column to the right hand column. The topics moved were all of the trigonometry, vectors and parametric equations.
And so concluded a successful morning – we even finished in time for Christmas lunch!











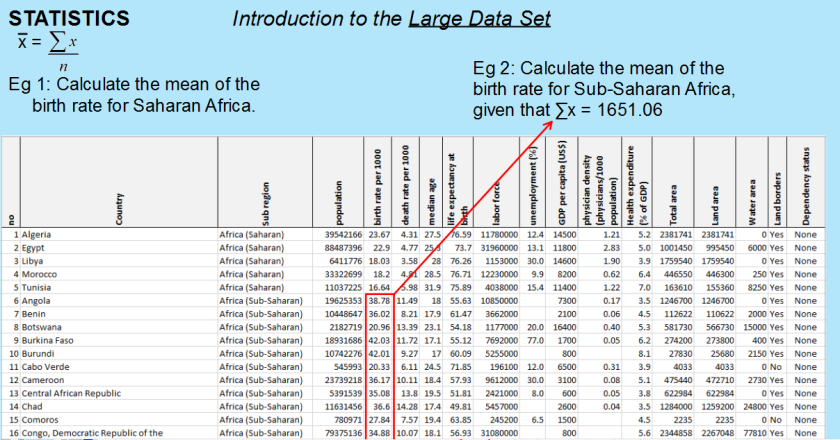


 This question from the MEI sample A Level assessment – we were drawn to the very long tail at the bottom of the Sub-Saharan Africa box-plot, and wondered which countries were causing this. Looking at the LDS we quickly came up with 3 countries with very low birth rates: Saint Helena, Mauritius, Seychelles – all island nations. Which feels like a nice fact – that the island nations of Sub Saharan Africa have significantly lower birth rates than other countries in that region.
This question from the MEI sample A Level assessment – we were drawn to the very long tail at the bottom of the Sub-Saharan Africa box-plot, and wondered which countries were causing this. Looking at the LDS we quickly came up with 3 countries with very low birth rates: Saint Helena, Mauritius, Seychelles – all island nations. Which feels like a nice fact – that the island nations of Sub Saharan Africa have significantly lower birth rates than other countries in that region.
 Problem 1
Problem 1
 Problem 3
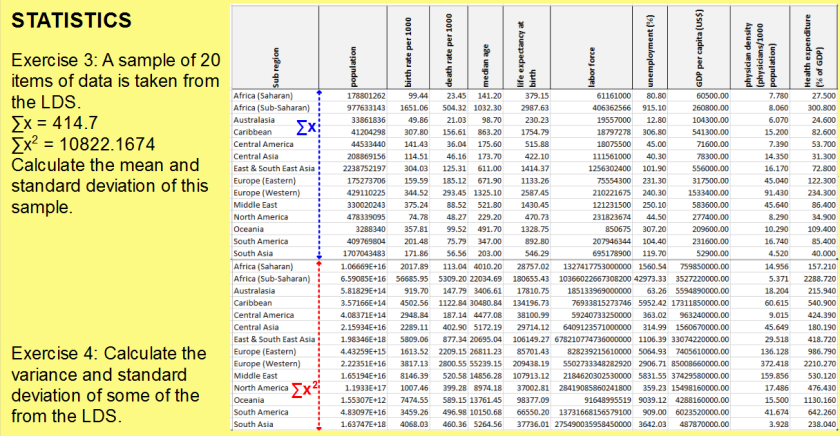
Problem 3 Looking at the questions in the specimen paper, students are expected to be able to recall information about the average amounts of certain food groups from different regions. This is something that could only be known by someone who has done extensive work with the data set before, and given the sheer scale of the data is unlikely to be something that you could repeat for all of the different food groups.
Looking at the questions in the specimen paper, students are expected to be able to recall information about the average amounts of certain food groups from different regions. This is something that could only be known by someone who has done extensive work with the data set before, and given the sheer scale of the data is unlikely to be something that you could repeat for all of the different food groups.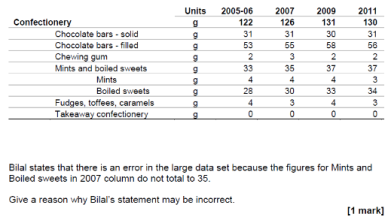 Later questions involving the data set give a small excerpt and ask questions about these. These are much more accessible to students who do not have as much familiarity, but will be easier for those who are aware of the context. For example there is question about the total amount of confectionery purchased, which does not state that it is based on averages.
Later questions involving the data set give a small excerpt and ask questions about these. These are much more accessible to students who do not have as much familiarity, but will be easier for those who are aware of the context. For example there is question about the total amount of confectionery purchased, which does not state that it is based on averages. In the question pictured here it would be advantageous to be familiar with the data set, particularly for part (ii), as there are different codes for the authorities based on their type. If you knew this then you would know how to separate the authorities further and would merely have to explain this.
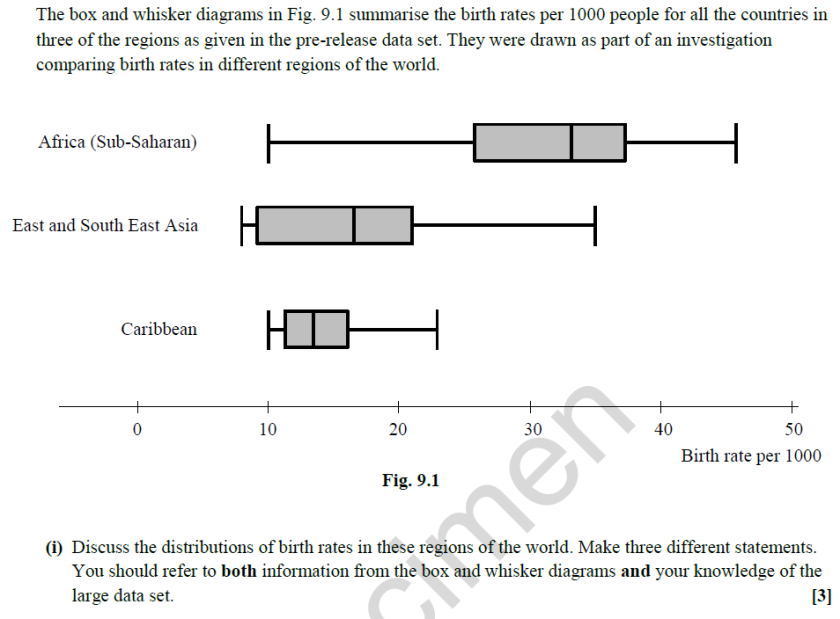
In the question pictured here it would be advantageous to be familiar with the data set, particularly for part (ii), as there are different codes for the authorities based on their type. If you knew this then you would know how to separate the authorities further and would merely have to explain this.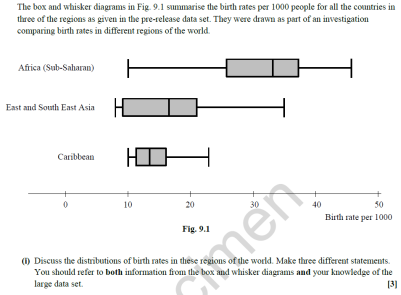 The data set that is available for the specimen papers is far less ‘large’ than the others, reducing to two A3 sheets. The question included here really grabbed me as being interesting – what were the outliers in Sub-Saharan Africa? On inspection, the data that stood out was that from islands, rather than countries on the continent.
The data set that is available for the specimen papers is far less ‘large’ than the others, reducing to two A3 sheets. The question included here really grabbed me as being interesting – what were the outliers in Sub-Saharan Africa? On inspection, the data that stood out was that from islands, rather than countries on the continent. The questions based on this data set again seemed to not require much detailed knowledge of the readings. In the question shown here it is only the fact that there is one reading per day that will help with part (b).
The questions based on this data set again seemed to not require much detailed knowledge of the readings. In the question shown here it is only the fact that there is one reading per day that will help with part (b).